第7节 高质量的Makefile
❤️💕💕During the winter vacation, I followed up and learned two projects: tiktok project and IAM project, and summarized and practiced the CloudNative project and Go language. I learned a lot in the process.Myblog:http://nsddd.top
[TOC]
低质量的makefile
低质量的 Makefile 文件是什么样的;
build: clean vet
@mkdir -p ./Role
@export GOOS=linux && go build -v .
vet:
go vet ./...
fmt:
go fmt ./...
clean:
rm -rf dashboard
上面这个 Makefile 存在不少问题。例如:功能简单,只能完成最基本的编译、格式化等操作,像构建镜像、自动生成代码等一些高阶的功能都没有;扩展性差,没法编译出可在 Mac 下运行的二进制文件;没有 Help 功能,使用难度高;单 Makefile 文件,结构单一,不适合添加一些复杂的管理功能。
所以,我们不光要编写 Makefile,还要编写高质量的 Makefile。那么如何编写一个高质量的 Makefile 呢?我觉得,可以通过以下 4 个方法来实现:
- 打好基础,也就是熟练掌握
Makefile的语法。 - 做好准备工作,也就是提前规划
Makefile要实现的功能。 - 进行规划,设计一个合理的
Makefile结构。 - 掌握方法,用好
Makefile的编写技巧。
makefile 如何工作

makefile规则:
target ... : prerequisites ...
command
...
...
- target
- 可以是一个object file(目标文件),也可以是一个执行文件,还可以是一个标签(label)。对于标签这种特性,在后续的“伪目标”章节中会有叙述。
- prereqisites
- 生成该target所依赖的文件和/或target
- command
- 该target要执行的命令(任意的shell命令)
prerequisites中如果有一个以上的文件比target文件要新的话,command所定义的命令就会被执行。
Build and Run
首先两个特别频繁的指令加进去:
build:
go build -o stringifier main.go
run:
go run -race main.gobuild:
我在运行命令中添加了-race标志,方便它在运行时在Go代码中检测到race情况。
Cleaning and DRYing
构建二进制文件并运行应用程序后,一切正常, 确保我们在执行其他任何操作之前先清理二进制文件。我们更新Makefile应该看起来像这样:
clean:
go clean:
我们有两点可以改进:
- 我们明确地重用了我们的应用程序名, 很自然我们的应用程序名称将在整个
Makefile中的许多地方使用。 - 每次构建应用之前,我们需要先执行
clean的规则。
改进后的Makefile
APP=stringifier
build: clean
go build -o ${APP} main.go
run:
go run -race main.go
clean:
go clean
更新: 这个例子之前使用的rm -r ${APP},现在使用go clean。
在顶部定义Makefile变量,当您调用make命令时make将自动引用它们,这样Makefile看起来就更整洁、规范了。
PHONY targets
在 Makefile 中,.PHONY 是一个特殊的目标(target),它用于定义那些不表示实际文件的伪目标(phony target)。
当 Makefile 执行时,它会检查定义的目标是否已经存在或是否需要更新。对于伪目标,由于它们不表示任何实际文件,因此 Makefile 无法检查它们是否已经存在或是否需要更新。为了避免误判,可以使用 .PHONY 来明确告诉 Makefile 哪些目标是伪目标,以便在执行时跳过对这些目标的检查。
例如,假设 Makefile 中定义了一个 clean 目标用于删除生成的文件,但是 clean 并不表示任何实际的文件,只是一个伪目标。那么,为了确保 Makefile 在执行时不会将 clean 当成一个文件来检查,可以在 Makefile 中添加如下声明:
.PHONY: clean
clean:
rm -f *.o myprogram
这样,当执行 "make clean" 命令时,Makefile 会跳过对 clean 目标的文件检查,直接执行清理命令。同时,如果我们在 Makefile 中定义了一个与 clean 相同名字的文件,Makefile 也不会将其与 clean 目标混淆。因此,使用
.PHONY声明伪目标可以提高 Makefile 的可读性和可靠性。
默认情况下,如果一个前置条件或是目录文件已更改,make将执行规则。但是由于我们不依赖于make来检测文件更改的能力,因此我们会遇到潜在的麻烦。
假设我们的项目目录中有一个名为 build 的文件, 在这个场景下,当你执行make build, make一定会检查文件build的更改,由于没有前置条件,因此将始终将build文件视为最新的,并且不会执行其规则定义的操作。
为了避免这个问题,你需要先知道.PHONY 特殊目录(target)是什么意思:特殊目标.PHONY的先决条件被视为phony目标(targets)。 当需要运行时,make会无条件运行其规则,而不管该名称的文件是否存在或其最后修改时间是多少。
所以,你可以通过将目标(target)指定为特殊目标.PHONY的先决条件,将目标指定为.PHONY。
APP=stringifier
.PHONY: build
build: clean
go build -o ${APP} main.go
.PHONY: run
run:
go run -race main.go
.PHONY: clean
clean:
go clean
现在你已将上述所有的targets指定为phony, 每次你调用任何phony目标(target) 时,make将会执行相应的规则。你还可以一次将所有要指定为phony的目标指定为:
.PHONY: build clean run
但是对于非常大的Makefile,不建议这样做因为这可能导致歧义和无法读取。因此,首选方法是在规则定义之前显式设置phony目标(target)。
Recursive Make targets
当 Makefile 包含多个目标时,我们可以在 Makefile 中使用递归 Make 来构建这些目标。递归 Make 指的是在 Makefile 中调用另一个 Makefile 来构建其中的目标。
在递归 Make 中,通常有一个顶层 Makefile,该 Makefile 调用其他 Makefile 来构建子目录中的目标。这样的 Makefile 被称为 "递归 Makefile",而由这个 Makefile 调用的 Makefile 被称为 "子 Makefile"。
在递归 Make 中,每个子 Makefile 负责构建它所在的目录中的目标,然后将构建的结果返回给父 Makefile。递归 Make 的一个常见的问题是,当在子目录中调用 Make 命令时,可能会破坏父目录中的变量设置和规则,因此需要小心地设置变量和规则,以避免不必要的冲突。
递归 Make 的一种常见用法是使用一个称为“递归变量”的特殊变量。递归变量的值可以包含调用另一个 Makefile 的命令,这个命令会返回一个值,可以被递归变量使用。递归变量在递归 Make 中非常有用,因为它们可以帮助子 Makefile 获得父 Makefile 中的变量值。
例如,我们可以在项目的根目录下创建一个名为 "Makefile" 的文件,其内容如下:
SUBDIRS = foo bar baz
.PHONY: all $(SUBDIRS)
all: $(SUBDIRS)
$(SUBDIRS):
$(MAKE) -C $@
在上面的 Makefile 中,"SUBDIRS" 变量定义了项目的子目录名称。"all" 是一个伪目标,它将调用每个子目录中的 Makefile 来构建所有目标。
$(SUBDIRS) 是一个自动变量,它会展开为 "foo bar baz"。因此,当我们运行 "make all" 命令时,它将首先调用 "make foo",然后在 "foo" 目录中运行 "make" 命令来构建 "foo" 目录中的目标。接着它会依次调用 "make bar" 和 "make baz" 命令,以此类推。
在子目录的 Makefile 中,我们可以使用和普通 Makefile 中一样的规则和变量定义来构建子目录中的目标。这种方式可以帮助我们轻松地管理复杂的项目,避免代码重复,并提高 Makefile 的可重用性。
现在让我们假设我们在项目中使用的根目录中还有另一个模块tokenizer。现在我们的目录结构是这样的:
~/programming/stringifier
.
├── main.go
├── Makefile
└── tokenizer/
├── main.go
└── Makefile~/programming/stringifier
很自然,某些时候我们也想build和test我们的tokenizer模块。由于它是一个独立的模块也可能是一个独立的项目,在它的目录有如下内容的一个Makefile是很有必要的:
# ~/programming/stringifier/tokenizer/Makefile
APP=tokenizer
build:
go build -o ${APP} main.go
现在只要您在stringifier项目的根目录中并且想要构建tokenizer应用程序,你不会想使用诸如cd tokenizer && make build && cd - 这样的易受攻击的命令行技巧,而具体的Makefiles的规则写在子目录中的方式。幸运的是,make可以帮助你解决这个问题。你可以使用-C标志和特殊的${NAME}变量在其他目录中调用make targets。下面是stringifies项目最初的Makefile:
# ~/programming/stringifier/Makefile
APP=stringifier
.PHONY: build
build: clean
go build -o ${APP} main.go
.PHONY: run
run:
go run -race main.go
.PHONY: clean
clean:
go clean
.PHONY: build-tokenizer
build-tokenizer:
${MAKE} -C tokenizer build
现在只要你运行make build-tokenizer,make都将为您处理目录切换,并以更加可读和健壮的方式为您调用正确目录中的正确目标
-c 标志和特殊的 ${NAME}:
-C标志:指定 Makefile 文件的目录,让 make 命令在指定的目录下执行 Makefile 文件。例如:all: cd subdir && $(MAKE)上述 Makefile 中的
$(MAKE)命令会在当前目录下的subdir目录中执行 Makefile 文件。可以使用-C标志来达到同样的效果:all: $(MAKE) -C subdir${NAME}变量:在 Makefile 中使用${NAME}变量可以引用环境变量中的值,例如:all: echo "PATH is ${PATH}"上述 Makefile 中的
${PATH}变量会展开为当前系统环境变量中的PATH值。
以下是一个用 Go 语言编写的 Makefile 示例,其中使用了 -C 标志和 ${NAME} 变量:
# Makefile
APP_NAME := my-app
.PHONY: build
build:
cd cmd/my-app && go build -o ../../bin/$(APP_NAME)
.PHONY: test
test:
go test ./...
.PHONY: clean
clean:
rm -rf bin/*
.PHONY: build-docker
build-docker: build
docker build -t $(APP_NAME) .
.PHONY: run-docker
run-docker: build-docker
docker run -p 8080:8080 $(APP_NAME)
.PHONY: deploy
deploy: build-docker
ssh ${SSH_USER}@${SSH_HOST} "docker pull $(APP_NAME); docker stop $(APP_NAME) || true; docker rm $(APP_NAME) || true; docker run -p 8080:8080 -d --name $(APP_NAME) $(APP_NAME)"
上述 Makefile 中,build-docker、run-docker 和 deploy 等目标中使用了 ${APP_NAME} 变量来指定 Docker 镜像的名称,同时使用了 -C 标志来在子目录中执行命令,例如 build 目标中的 cd cmd/my-app && go build 命令。
Targets for Docker commands
现在您希望对应用程序进行容器化,然后为方便起见编写make目标,这是完全可以理解的。
你为docker命令定义了如下规则:
.PHONY: docker-build
docker-build: build
docker build -t stringifier .
docker tag stringifier stringifier:tag
.PHONY: docker-push
docker-push: docker-build
docker push gcr.io/stringifier/stringifier-staging/stringifier:tag
docker命令基本满足需要,但是还有改善的空间,
- 对于新手,你可以再次重用你的
${APP}变量。 - 接下来,您想要更灵活并确保可以轻松控制将映像推送到哪里,无论是您的私人镜像仓库还是其他地方。
- 然后,您希望能够根据用户在命令行上的某些输入将镜像(image)分别推送到与预生产和生产环境有关的两个单独的镜像仓库中。
- 最后,像一个理智的开发人员一样,您想使用当前的
git commit sha标记您的镜像(image)。 让我们基于这些问题重新修改下Makefile:
APP?=application
REGISTRY?=gcr.io/images
COMMIT_SHA=$(shell git rev-parse --short HEAD)
.PHONY: docker-build
docker-build: build
docker build -t ${APP} .
docker tag ${APP} ${APP}:${COMMIT_SHA}
.PHONY: docker-push
docker-push: check-environment docker-build
docker push ${REGISTRY}/${ENV}/${APP}:${COMMIT_SHA}
check-environment:
ifndef ENV
$(error ENV not set, allowed values - `staging` or `production`)
endif
现在,让我们回顾下上面的更改:
- 你开始为应用程序名称,镜像名称,提交sha使用变量。
- 您使用特殊的shell函数生成了commit sha。 在这种情况下,您运行了git命令,该命令返回了简短的提交sha,并将其分配给变量
${COMMIT_SHA},以便稍后在Makefile中使用。 - 您添加了一个新的规则
check-environment,该环境使用make条件检查在调用make时是否指定了ENV变量,这有助于区分预生产及生产环境。
check-environment的规则如下:
check-environment:
ifndef ENV
$(error ENV not set, allowed values - `staging` or `production`)
endif
使用ifndef指令检查变量ENV是否为空值,如果存在,则使用另一个make的提供内置函数,如果出错了,将会在关键字之后抛出具体的错误消息。
$ make docker-push
Makefile:33: *** ENV not set, allowed values - `staging` or `production`. Stop.
$ ENV=staging make docker-push
Success
本质上,您要确保docker-push目标具有安全保障,该保障可检查调用目标的用户是否已为ENV变量指定值。
@ 符号
项目的 makefile 中很容易看到 @ 符号的存在,它的意义不同寻常:
## build: Build source code for host platform.
.PHONY: build
build:
@$(MAKE) go.build
在Makefile中,@符号用于 抑制Make命令的输出。当在Makefile中使用@符号时,Make将不会打印出该行命令的输出结果,而是仅仅执行该命令。
在Go语言项目中,我们通常使用Makefile来构建和管理项目。下面是一个简单的Go语言项目Makefile示例:
# 编译二进制文件
build:
@go build -o myapp main.go
# 运行程序
run:
@./myapp
# 清理
clean:
@rm -f myapp
在上面的示例中,我们定义了三个Makefile命令:build,run和clean。在每个命令的前面,我们都使用了@符号来抑制命令的输出。这意味着,当我们在命令行中运行make build时,Make命令将会编译Go程序,但不会将编译器的输出打印到终端。
如果我们去掉@符号,那么当我们运行make build时,Make将会输出编译器的输出,类似于下面的结果:
go build -o myapp main.go
# 输出编译器的输出
因此,使用@符号可以使Makefile输出更加干净,仅仅打印出我们关心的内容,而不会输出一堆不必要的信息。
文件搜索 VPATH
在一些大的工程中,有大量的源文件,我们通常的做法是把这许多的源文件分类,并存放在不同的目录中。所以,当make需要去找寻文件的依赖关系时,你可以在文件前加上路径,但最好的方法是把一个路径告诉make,让make在自动去找。
Makefile文件中的特殊变量 VPATH 就是完成这个功能的,如果没有指明这个变量,make只会在当前的目录中去找寻依赖文件和目标文件。如果定义了这个变量,那么,make就会在当前目录找不到的情况下,到所指定的目录中去找寻文件了。
VPATH = src:../headers
上面的定义指定两个目录,“src”和“../headers”,make会按照这个顺序进行搜索。目录由“冒号”分隔。(当然,当前目录永远是最高优先搜索的地方)
另一个设置文件搜索路径的方法是使用make的“vpath”关键字(注意,它是全小写的),这不是变量,这是一个make的关键字,这和上面提到的那个VPATH变量很类似,但是它更为灵活。它可以指定不同的文件在不同的搜索目录中。这是一个很灵活的功能。它的使用方法有三种:
vpath <pattern> <directories>
为符合模式<pattern>的文件指定搜索目录<directories>。
vpath <pattern>
清除符合模式<pattern>的文件的搜索目录。
vpath
清除所有已被设置好了的文件搜索目录。
Help target
一个新成员加入了该项目并想知道Makefile中所有规则的作用,为帮助它们您可以添加一个新目标(target),该目标将打印所有目标名称以及它们作用的简短描述:
.PHONY: build
## build: build the application
build: clean
@echo "Building..."
@go build -o ${APP} main.go
.PHONY: run
## run: runs go run main.go
run:
go run -race main.go
.PHONY: clean
## clean: cleans the binary
clean:
@echo "Cleaning"
@go clean
.PHONY: setup
## setup: setup go modules
setup:
@go mod init \
&& go mod tidy \
&& go mod vendor
.PHONY: help
## help: prints this help message
help:
@echo "Usage: \n"
@sed -n 's/^##//p' ${MAKEFILE_LIST} | column -t -s ':' | sed -e 's/^/ /'
你先注意下最后一条规则,help 在这里,您只是使用一些sed魔术来解析和在命令行上打印。 但是要做到这一点,您必要在每条规则之前写了目标名称和简短描述作为注释。 注意另一个特殊变量$ {MAKEFILE_LIST},它是您所引用的所有Makefile的列表,在本例中仅是Makefile。
您会将文件Makefile作为输入传递给sed命令,该命令将解析所有帮助注释并以表格格式将其打印到stdout,以便于阅读。 上一个代码段的help目标的输出如下所示:
$ make help
Usage:
build Build the application
clean cleans the binary
run runs go run main.go
docker-build builds docker image
docker-push pushes the docker image
setup set up modules
help prints this help message
这些消息很有帮助,对于其他人甚至有时对自己都是一个不错的提示。
Conclusion 结论
Make是一个简单但可高度配置的工具。 在本文中,您遍历了make提供的许多配置和功能,从而为Go应用程序编写了有效而高效的Makefile。
下面是完整的Makefile,其中添加了一些琐碎的规则和变量:
GO111MODULES=on
APP?=stringifier
REGISTRY?=gcr.io/images
COMMIT_SHA=$(shell git rev-parse --short HEAD)
.PHONY: build
## build: build the application
build: clean
@echo "Building..."
@go build -o ${APP} main.go
.PHONY: run
## run: runs go run main.go
run:
go run -race main.go
.PHONY: clean
## clean: cleans the binary
clean:
@echo "Cleaning"
@go clean
.PHONY: test
## test: runs go test with default values
test:
go test -v -count=1 -race ./...
.PHONY: build-tokenizer
## build-tokenizer: build the tokenizer application
build-tokenizer:
${MAKE} -c tokenizer build
.PHONY: setup
## setup: setup go modules
setup:
@go mod init \
&& go mod tidy \
&& go mod vendor
# helper rule for deployment
check-environment:
ifndef ENV
$(error ENV not set, allowed values - `staging` or `production`)
endif
.PHONY: docker-build
## docker-build: builds the stringifier docker image to registry
docker-build: build
docker build -t ${APP}:${COMMIT_SHA} .
.PHONY: docker-push
## docker-push: pushes the stringifier docker image to registry
docker-push: check-environment docker-build
docker push ${REGISTRY}/${ENV}/${APP}:${COMMIT_SHA}
.PHONY: help
## help: Prints this help message
help:
@echo "Usage: \n"
@sed -n 's/^##//p' ${MAKEFILE_LIST} | column -t -s ':' | sed -e 's/^/ /'
熟练makefile语法
IAM 项目的 Makefile 文件:
$ make help
Usage: make <TARGETS> <OPTIONS> ...
Targets:
# 代码生成类命令
gen Generate all necessary files, such as error code files.
# 格式化类命令
format Gofmt (reformat) package sources (exclude vendor dir if existed).
# 静态代码检查
lint Check syntax and styling of go sources.
# 测试类命令
test Run unit test.
cover Run unit test and get test coverage.
# 构建类命令
build Build source code for host platform.
build.multiarch Build source code for multiple platforms. See option PLATFORMS.
# Docker镜像打包类命令
image Build docker images for host arch.
image.multiarch Build docker images for multiple platforms. See option PLATFORMS.
push Build docker images for host arch and push images to registry.
push.multiarch Build docker images for multiple platforms and push images to registry.
# 部署类命令
deploy Deploy updated components to development env.
# 清理类命令
clean Remove all files that are created by building.
# 其他命令,不同项目会有区别
release Release iam
verify-copyright Verify the boilerplate headers for all files.
ca Generate CA files for all iam components.
install Install iam system with all its components.
swagger Generate swagger document.
tools install dependent tools.
# 帮助命令
help Show this help info.
# 选项
Options:
DEBUG Whether to generate debug symbols. Default is 0.
BINS The binaries to build. Default is all of cmd.
This option is available when using: make build/build.multiarch
Example: make build BINS="iam-apiserver iam-authz-server"
...
通常而言,Go 项目的 Makefile 应该实现以下功能:格式化代码、静态代码检查、单元测试、代码构建、文件清理、帮助等等。如果通过 docker 部署,还需要有 docker 镜像打包功能。因为 Go 是跨平台的语言,所以构建和 docker 打包命令,还要能够支持不同的 CPU 架构和平台。为了能够更好地控制 Makefile 命令的行为,还需要支持 Options。
为了方便查看 Makefile 集成了哪些功能,我们需要支持 help 命令。help 命令最好通过解析 Makefile 文件来输出集成的功能,例如:
## help: Show this help info.
.PHONY: help
help: Makefile
@echo -e "\nUsage: make <TARGETS> <OPTIONS> ...\n\nTargets:"
@sed -n 's/^##//p' $< | column -t -s ':' | sed -e 's/^/ /'
@echo "$$USAGE_OPTIONS"
上面的 help 命令,通过解析 Makefile 文件中的 ## 注释,获取支持的命令。通过这种方式,我们以后新加命令时,就不用再对 help 命令进行修改了。
常用的 Makefile 核心语法
大多数的 make 都支持“makefile”和“Makefile”这两种文件名,但我建议使用“Makefile”。因为这个文件名第一个字符大写,会很明显,容易辨别。make 也支持 -f 和 --file 参数来指定其他文件名,比如 make -f golang.mk 或者 make --file golang.mk 。
makefile 支持的通配符
Makefile 支持三种类型的通配符,他们是:*,? 和~
*通配符:
*通配符代表任意长度的字符序列,可以匹配任意长度的文件名或路径名中的任意字符。例如,可以使用以下规则来匹配所有.c文件:
SRCS := $(wildcard *.c)
这条规则将会将当前目录下所有以.c为后缀的文件名赋值给变量SRCS,使得我们可以方便地引用这些文件。
?通配符:
?通配符代表任意单个字符,可以匹配任意长度的文件名或路径名中的一个字符。例如,可以使用以下规则来匹配所有三个字符长的.txt文件:
SRCS := $(wildcard ???.txt)
这条规则将会将当前目录下所有文件名长度为3,并以.txt为后缀的文件名赋值给变量SRCS。
~通配符:
~通配符代表当前用户的home目录,可以用来指定文件路径。例如,可以使用以下规则来指定当前用户的home目录:
$(HOME)~/myprogram
这条规则将会将当前用户的home目录路径和myprogram字符串拼接起来,从而得到一个完整的路径名,使得我们可以方便地引用home目录下的文件或路径。
变量
变量,可能是 Makefile 中使用最频繁的语法了,Makefile 支持变量赋值、多行变量和环境变量。另外,Makefile 还内置了一些特殊变量和自动化变量。
变量赋值 :
Makefile 也可以像其他语言一样支持变量。在使用变量时,会像 shell 变量一样原地展开,然后再执行替换后的内容。
Makefile 可以通过变量声明来声明一个变量,变量在声明时需要赋予一个初值,比如ROOT_PACKAGE=github.com/marmotedu/iam。
引用变量时可以通过$()或者${}方式引用。我的建议是,用$()方式引用变量,例如$(ROOT_PACKAGE),也建议整个 makefile 的变量引用方式保持一致。
变量会像 bash 变量一样,在使用它的地方展开。比如:
GO=go
build:
$(GO) build -v .
展开后为:
GO=go
build:
go build -v .
Makefile 有四种的赋值方式:
= 最基本的赋值方法。
BASE_IMAGE = alpine:3.10
💡 注意:使用
=赋值的时候,取值到的并非是程序依次执行的值,而是最终的值A = a B = $(A) b A = cB 最后的值为 c b,而不是 a b。也就是说,在用变量给变量赋值时,右边变量的取值,取的是最终的变量值。
和go一样,:=直接赋值,赋予当前位置的值。
A = a
B := $(A) b
A = c
B 最后的值为 a b。通过 := 的赋值方式,可以避免 = 赋值带来的潜在的不一致。
?= 表示如果该变量没有被赋值,则赋予等号后的值。
例如:
PLATFORMS ?= linux_amd64 linux_arm64
+=表示将等号后面的值添加到前面的变量上。
MAKEFLAGS += --no-print-directory
Makefile 还支持多行变量。可以通过 define 关键字设置多行变量,变量中允许换行。定义方式为:
define 变量名
变量内容
...
endef
变量的内容可以包含函数、命令、文字或是其他变量。例如,我们可以定义一个 USAGE_OPTIONS 变量:
define USAGE_OPTIONS
Options:
DEBUG Whether to generate debug symbols. Default is 0.
BINS The binaries to build. Default is all of cmd.
...
V Set to 1 enable verbose build. Default is 0.
endef
Makefile 还支持环境变量。在 Makefile 中,有两种环境变量,分别是 Makefile 预定义的环境变量和自定义的环境变量。
其中,自定义的环境变量可以覆盖 Makefile 预定义的环境变量。默认情况下,Makefile 中定义的环境变量只在当前 Makefile 有效,如果想向下层传递(Makefile 中调用另一个 Makefile),需要使用 export 关键字来声明。
...
export USAGE_OPTIONS
...
此外,Makefile 还支持两种内置的变量:特殊变量和自动化变量。
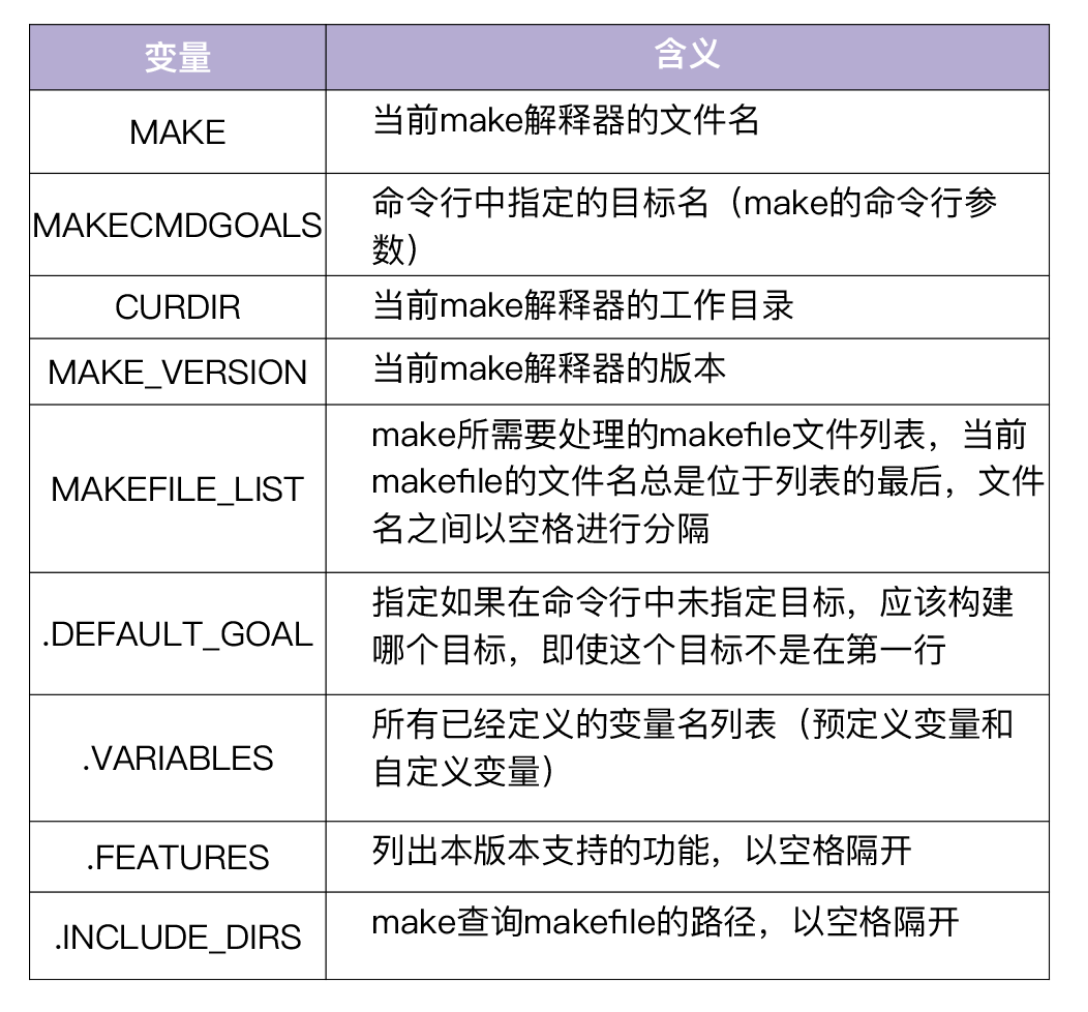
特殊变量是 make 提前定义好的,可以在 makefile 中直接引用。特殊变量列表如下:
Makefile 还支持自动化变量。自动化变量可以提高我们编写 Makefile 的效率和质量。
自动化变量:
自动化变量也叫做系统变量,这个是非常有用的,一个好的 Makefile 工作者不亚于 bash 的脚本小子,自动化变量占比非常高:
| 变量 | 用途 |
|---|---|
$@ | 表示规则的目标文件名 |
$% | 当目标文件是一个静态库文件时,代表静态库的一个成员名 |
$< | 规则的第一个依赖的文件名 |
$? | 所有目标文件更新的依赖文件列表,空格分隔 |
$^ | 代表的是所有依赖文件列表,使用空格分隔 |
$+ | 类似$^,但是它保留了依赖文件中重复出现的文件。主要用在程序链接时库的交叉引用场合。 |
$* | 在模式规则和静态模式规则中,代表“茎”。“茎”是目标模式中“%”所代表的部分(当文件名中存在目录时, “茎”也包含目录部分)。 |
$(@D) | 表示文件的目录部分(不包括斜杠)。如果 $@ 表示的是 dir/foo.o 那么 $(@D) 表示的值就是 dir。如果 $@ 不存在斜杠(文件在当前目录下),其值就是 . |
$(@F) | 表示的是文件除目录外的部分(实际的文件名)。如果 $@ 表示的是 dir/foo.o,那么 $@F 表示的值为 foo.o |
💡简单的一个案例如下:
test:test.o test1.o test2.o
gcc -o $@ $^ #等同于gcc -o test test.o test1.o test2.o
test.o:test.c test.h
gcc -o $@ $<
test1.o:test1.c test1.h
gcc -o $@ $<
test2.o:test2.c test2.h
gcc -o $@ $< #等同于gcc -o test2.o test2.c
这时就可以用到自动化变量。所谓自动化变量,就是这种变量会把模式中所定义的一系列的文件自动地挨个取出,一直到所有符合模式的文件都取完为止。这种自动化变量只应出现在规则的命令中。Makefile 中支持的自动化变量见下表。
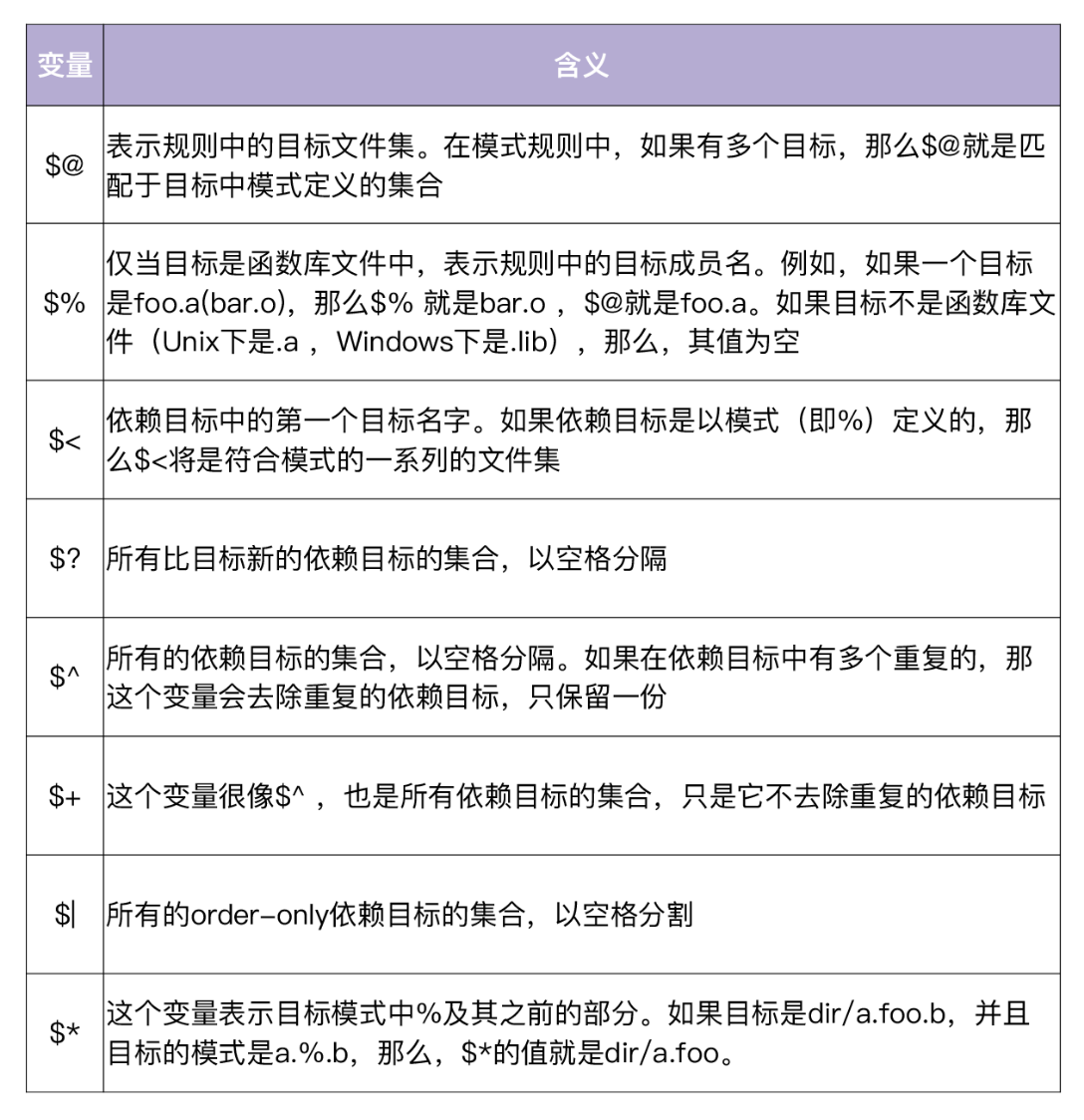
上面这些自动化变量中,$*是用得最多的。$* 对于构造有关联的文件名是比较有效的。如果目标中没有模式的定义,那么 $* 也就不能被推导出。但是,如果目标文件的后缀是 make 所识别的,那么 $* 就是除了后缀的那一部分。例如:如果目标是 foo.c ,因为.c 是 make 所能识别的后缀名,所以 $* 的值就是 foo。
$*是一个自动变量,表示目标的名称,即这个规则被应用于哪个目标。例如,如果在命令行上输入make tools.install.foo,那么$*的值将是foo。在 Makefile 规则中,可以使用$*来引用目标名称,例如:build.%: go build -o bin/$* ./cmd/$*这个规则将编译
cmd目录下的 Go 程序,并将编译结果放置到bin目录中。例如,如果输入make build.server,那么将编译cmd/server目录下的 Go 程序,并将编译结果放置到bin/server目录中。
条件语句:
Makefile 也支持条件语句。这里先看一个示例。
下面的例子判断变量ROOT_PACKAGE是否为空,如果为空,则输出错误信息,不为空则打印变量值:
ifeq ($(ROOT_PACKAGE),)
$(error the variable ROOT_PACKAGE must be set prior to including golang.mk)
else
$(info the value of ROOT_PACKAGE is $(ROOT_PACKAGE))
endif
条件语句的语法为:
# if ...
<conditional-directive>
<text-if-true>
endif
# if ... else ...
<conditional-directive>
<text-if-true>
else
<text-if-false>
endif
例如,判断两个值是否相等:
ifeq 条件表达式
...
else
...
endif
- ifeq 表示条件语句的开始,并指定一个条件表达式。表达式包含两个参数,参数之间用逗号分隔,并且表达式用圆括号括起来。
- else 表示条件表达式为假的情况。
- endif 表示一个条件语句的结束,任何一个条件表达式都应该以 endif 结束。
- 表示条件关键字,有 4 个关键字:ifeq、ifneq、ifdef、ifndef。
为了加深你的理解,我们分别来看下这 4 个关键字的例子。
ifeq:条件判断,判断是否相等。
ifeq (<arg1>, <arg2>)
ifeq '<arg1>' '<arg2>'
ifeq "<arg1>" "<arg2>"
ifeq "<arg1>" '<arg2>'
ifeq '<arg1>' "<arg2>"
比较 arg1 和 arg2 的值是否相同,如果相同则为真。也可以用 make 函数 / 变量替代 arg1 或 arg2,例如 ifeq ($(origin ROOT_DIR),undefined) 或 ifeq ($(ROOT_PACKAGE),) 。origin 函数会在之后专门讲函数的一讲中介绍到。
ifneq:条件判断,判断是否不相等。
ifneq (<arg1>, <arg2>)
ifneq '<arg1>' '<arg2>'
ifneq "<arg1>" "<arg2>"
ifneq "<arg1>" '<arg2>'
ifneq '<arg1>' "<arg2>"
比较 arg1 和 arg2 的值是否不同,如果不同则为真。
ifdef:条件判断,判断变量是否已定义。
ifdef <variable-name>
如果值非空,则表达式为真,否则为假。也可以是函数的返回值。
ifndef:条件判断,判断变量是否未定义。
ifndef <variable-name>
如果值为空,则表达式为真,否则为假。也可以是函数的返回值。
函数
我们先来看下自定义函数。 make 解释器提供了一系列的函数供 Makefile 调用,这些函数是 Makefile 的预定义函数。我们可以通过 define 关键字来自定义一个函数。自定义函数的语法为:
define 函数名
函数体
endef
💡简单的一个案例如下:
define Foo
@echo "my name is $(0)"
@echo "param is $(1)"
endef
define 本质上是定义一个多行变量,可以在 call 的作用下当作函数来使用,在其他位置使用只能作为多行变量来使用,例如:
var := $(call Foo)
new := $(Foo)
预定义函数:
再来看下预定义函数。 刚才提到,make 编译器也定义了很多函数,这些函数叫作预定义函数,调用语法和变量类似,语法为:
$(<function> <arguments>)
OR
${<function> <arguments>}
<function> 是函数名,<arguments> 是函数参数,参数间用逗号分割。函数的参数也可以是变量。
💡简单的一个案例如下:
PLATFORM = linux_amd64
GOOS := $(word 1, $(subst _, ,$(PLATFORM)))
上面的例子用到了两个函数:word 和 subst。word 函数有两个参数,1 和 subst 函数的输出。subst 函数将 PLATFORM 变量值中的 _ 替换成空格(替换后的 PLATFORM 值为 linux amd64)。word 函数取 linux amd64 字符串中的第一个单词。所以最后 GOOS 的值为 linux。
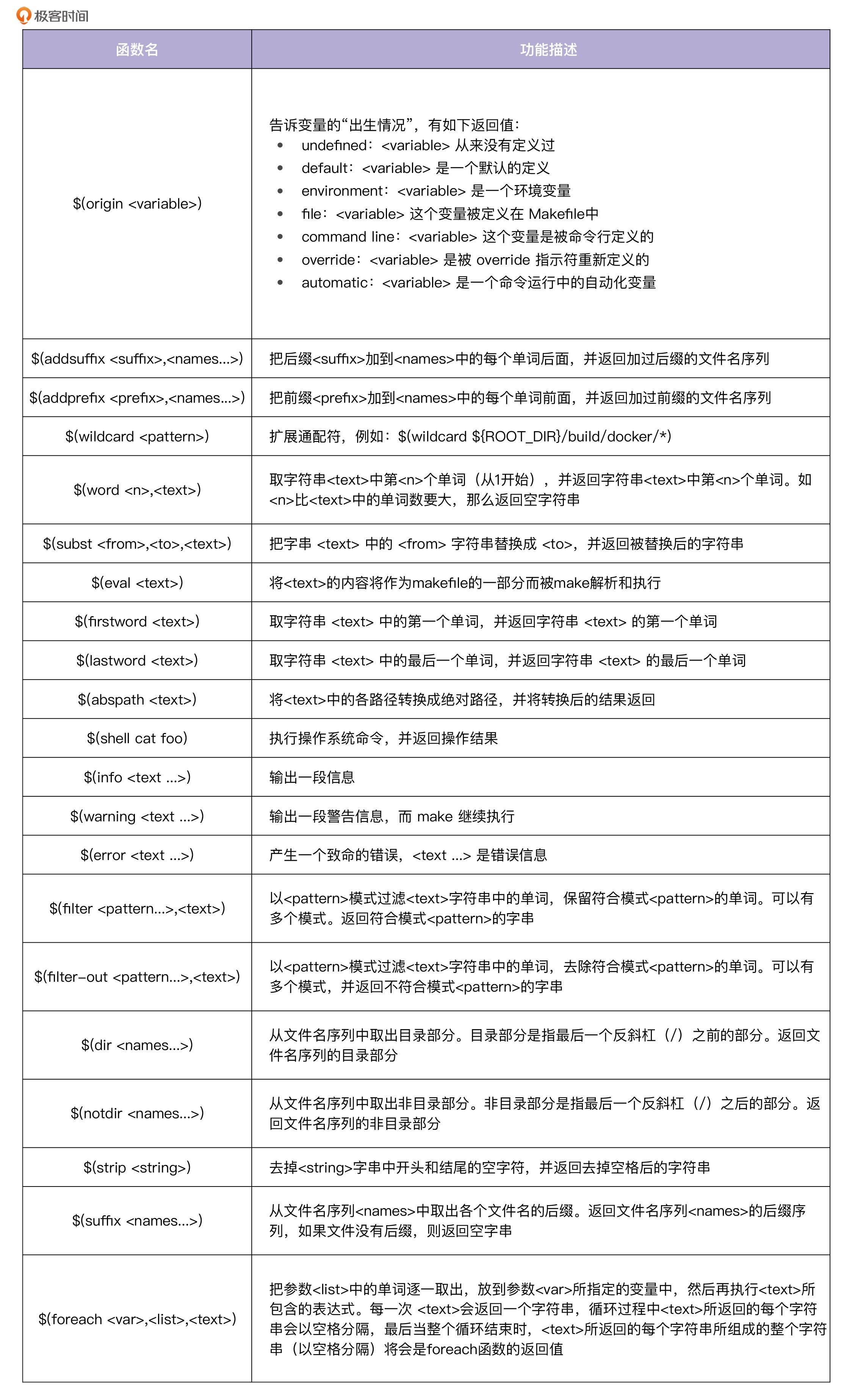
Makefile 预定义函数能够帮助我们实现很多强大的功能,在编写 Makefile 的过程中,如果有功能需求,可以优先使用这些函数。如果你想使用这些函数,那就需要知道有哪些函数,以及它们实现的功能。
引入其他 Makefile
在 Makefile 中,我们可以通过关键字 include,把别的 makefile 包含进来,类似于 C 语言的#include,被包含的文件会插入在当前的位置。include 用法为 include ,示例如下:
include scripts/make-rules/common.mk
include scripts/make-rules/golang.mk
include 也可以包含通配符include scripts/make-rules/*。make 命令会按下面的顺序查找 makefile 文件:
- 如果是绝对或相对路径,就直接根据路径 include 进来。
- 如果 make 执行时,有
-I或--include-dir参数,那么 make 就会在这个参数所指定的目录下去找。 - 如果目录
<prefix>/include(一般是/usr/local/bin或/usr/include)存在的话,make 也会去找。
如果有文件没有找到,make 会生成一条警告信息,但不会马上出现致命错误,而是继续载入其他的文件。一旦完成 makefile 的读取,make 会再重试这些没有找到或是不能读取的文件。如果还是不行,make 才会出现一条致命错误信息。如果你想让 make 忽略那些无法读取的文件继续执行,可以在 include 前加一个减号-,如-include 。
设计Makefile结构
对于大型项目来说,需要管理的内容很多,所有管理功能都集成在一个 Makefile 中,可能会导致 Makefile 很大,难以阅读和维护,所以建议采用分层的设计方法,根目录下的 Makefile 聚合所有的 Makefile 命令,具体实现则按功能分类,放在另外的 Makefile 中。
我们经常会在 Makefile 命令中集成 shell 脚本,但如果 shell 脚本过于复杂,也会导致 Makefile 内容过多,难以阅读和维护。并且在 Makefile 中集成复杂的 shell 脚本,编写体验也很差。对于这种情况,可以将复杂的 shell 命令封装在 shell 脚本中,供 Makefile 直接调用,而一些简单的命令则可以直接集成在 Makefile 中。
推荐的 Makefile 结构:
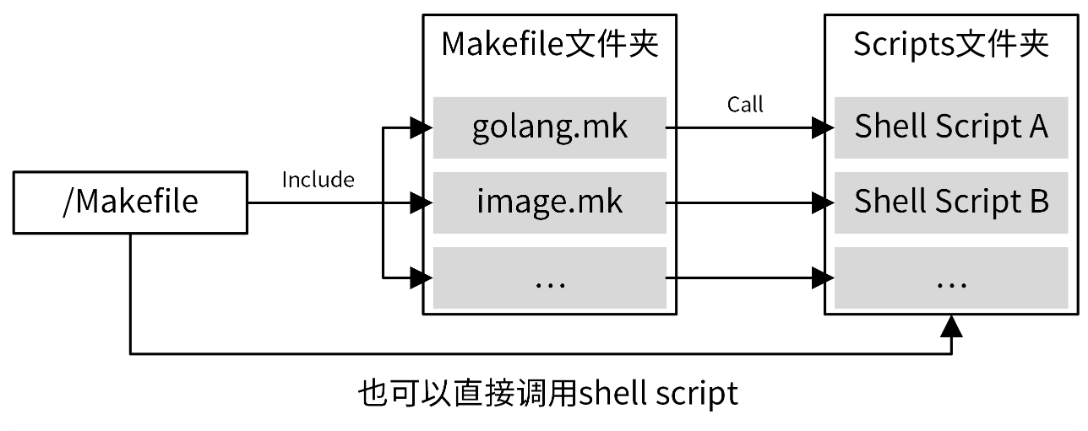
在上面的 Makefile 组织方式中,根目录下的 Makefile 聚合了项目所有的管理功能,这些管理功能通过 Makefile 伪目标的方式实现。同时,还将这些伪目标进行分类,把相同类别的伪目标放在同一个 Makefile 中,这样可以使得 Makefile 更容易维护。对于复杂的命令,则编写成独立的 shell 脚本,并在 Makefile 命令中调用这些 shell 脚本。
举个例子,下面是 IAM 项目的 Makefile 组织结构:
├── Makefile
├── scripts
│ ├── gendoc.sh
│ ├── make-rules
│ │ ├── gen.mk
│ │ ├── golang.mk
│ │ ├── image.mk
│ │ └── ...
└── ...
├── Makefile
├── scripts
│ ├── gendoc.sh
│ ├── make-rules
│ │ ├── gen.mk
│ │ ├── golang.mk
│ │ ├── image.mk
│ │ └── ...
└── ...
我们将相同类别的操作统一放在 scripts/make-rules 目录下的 Makefile 文件中。Makefile 的文件名参考分类命名,例如 golang.mk。最后,在 /Makefile 中 include 这些 Makefile。
需要使用
include来获取头文件:
include是一种指令,用于将另一个文件中的规则和变量导入到当前的makefile中。这样做可以让你的makefile更加模块化,易于维护和重用。注意和我们上面讲的模块化分配 Makefile 层级调用有些不一样。
下面是一个include的案例,假设我们有一个名为
main.c的源文件,它需要链接一个名为libfoo.a的静态库文件。我们可以将这些规则和变量定义在一个名为Makefile.inc的文件中,然后在我们的主makefile中使用include指令将其导入。CC = gcc CFLAGS = -Wall -Werror -g all: libfoo.a libfoo.a: foo.o ar rcs $@ $^ foo.o: foo.c foo.h $(CC) $(CFLAGS) -c $< clean: rm -f *.o libfoo.a主makefile文件:
include Makefile.inc main: main.c libfoo.a $(CC) $(CFLAGS) -o $@ $< -L. -lfoo .PHONY: clean clean: $(MAKE) -C . -f Makefile.inc clean rm -f maingo 语言Makefile 💡简单的一个案例如下:
# 定义变量 GOCMD=go GOBUILD=$(GOCMD) build GOCLEAN=$(GOCMD) clean BINARY_NAME=myapp BINARY_UNIX=$(BINARY_NAME)_unix all: deps build build: $(GOBUILD) -o $(BINARY_NAME) -v $(GOBUILD) -o $(BINARY_UNIX) -v deps: $(GOCMD) get -u github.com/golang/dep/cmd/dep dep ensure clean: $(GOCLEAN) rm -f $(BINARY_NAME) rm -f $(BINARY_UNIX) run: $(GOBUILD) -o $(BINARY_NAME) -v ./... ./$(BINARY_NAME) include docker.mk在上面的示例中,最后一行
include docker.mk引用了名为docker.mk的 Makefile 文件。这个文件中可能包含了一些 Docker 相关的命令,比如构建镜像、推送镜像等等。通过 include 指令,这些命令可以被自动引入到主 Makefile 文件中,从而实现更加高效和便捷的编译和构建。需要注意的是,include 指令的作用是将被引入的 Makefile 文件的内容直接复制到主 Makefile 文件中。因此,如果引入的文件中定义了和主 Makefile 文件中相同的变量或者规则,会发生命名冲突。因此,在编写被引入的 Makefile 文件时,应该避免使用和主 Makefile 文件相同的变量和规则名。
为了跟 Makefile 的层级相匹配,golang.mk 中的所有目标都按go.xxx这种方式命名。通过这种命名方式,我们可以很容易分辨出某个目标完成什么功能,放在什么文件里,这在复杂的 Makefile 中尤其有用。以下是 IAM 项目根目录下,Makefile 的内容摘录,你可以看一看,作为参考:
include scripts/make-rules/golang.mk
include scripts/make-rules/image.mk
include scripts/make-rules/gen.mk
include scripts/make-rules/...
## build: Build source code for host platform.
.PHONY: build
build:
@$(MAKE) go.build
## build.multiarch: Build source code for multiple platforms. See option PLATFORMS.
.PHONY: build.multiarch
build.multiarch:
@$(MAKE) go.build.multiarch
## image: Build docker images for host arch.
.PHONY: image
image:
@$(MAKE) image.build
## push: Build docker images for host arch and push images to registry.
.PHONY: push
push:
@$(MAKE) image.push
## ca: Generate CA files for all iam components.
.PHONY: ca
ca:
@$(MAKE) gen.ca
另外,一个合理的 Makefile 结构应该具有前瞻性。也就是说,要在不改变现有结构的情况下,接纳后面的新功能。这就需要你整理好 Makefile 当前要实现的功能、即将要实现的功能和未来可能会实现的功能,然后基于这些功能,利用 Makefile 编程技巧,编写可扩展的 Makefile。
这里需要你注意:上面的 Makefile 通过 .PHONY 标识定义了大量的伪目标,定义伪目标一定要加 .PHONY 标识,否则当有同名的文件时,伪目标可能不会被执行。
掌握 Makefile 编写技巧
技巧 1:善用通配符和自动变量
Makefile 允许对目标进行类似正则运算的匹配,主要用到的通配符是%。通过使用通配符,可以使不同的目标使用相同的规则,从而使 Makefile 扩展性更强,也更简洁。
我们的 IAM 实战项目中,就大量使用了通配符%,例如:go.build.%、ca.gen.%、deploy.run.%、tools.verify.%、tools.install.%等。
这里,我们来看一个具体的例子,tools.verify.%(位于scripts/make-rules/tools.mk文件中)定义如下:
tools.verify.%:
@if ! which $* &>/dev/null; then $(MAKE) tools.install.$*; fi
make tools.verify.swagger, make tools.verify.mockgen等均可以使用上面定义的规则,%分别代表了swagger和mockgen。
如果不使用%,则我们需要分别为tools.verify.swagger和tools.verify.mockgen定义规则,很麻烦,后面修改也困难。
另外,这里也能看出tools.verify.%这种命名方式的好处:
- tools 说明依赖的定义位于
scripts/make-rules/tools.mkMakefile 中; - verify说明
tools.verify.%伪目标属于 verify 分类,主要用来验证工具是否安装。通过这种命名方式,你可以很容易地知道目标位于哪个 Makefile 文件中,以及想要完成的功能。
另外,上面的定义中还用到了自动变量$*,用来指代被匹配的值swagger、mockgen。
技巧 2:善用函数
Makefile 自带的函数能够帮助我们实现很多强大的功能。所以,在我们编写 Makefile 的过程中,如果有功能需求,可以优先使用这些函数。我把常用的函数以及它们实现的功能整理在了 Makefile 常用函数列表 中,你可以参考下。
IAM 的 Makefile 文件中大量使用了上述函数,如果你想查看这些函数的具体使用方法和场景,可以参考 IAM 项目的 Makefile 文件 make-rules。
技巧 3:依赖需要用到的工具
如果 Makefile 某个目标的命令中用到了某个工具,可以将该工具放在目标的依赖中。这样,当执行该目标时,就可以指定检查系统是否安装该工具,如果没有安装则自动安装,从而实现更高程度的自动化。例如,/Makefile 文件中,format 伪目标,定义如下:
.PHONY: format
format: tools.verify.golines tools.verify.goimports
@echo "===========> Formating codes"
@$(FIND) -type f -name '*.go' | $(XARGS) gofmt -s -w
@$(FIND) -type f -name '*.go' | $(XARGS) goimports -w -local $(ROOT_PACKAGE)
@$(FIND) -type f -name '*.go' | $(XARGS) golines -w --max-len=120 --reformat-tags --shorten-comments --ignore-generated .
你可以看到,format 依赖tools.verify.golines tools.verify.goimports。我们再来看下tools.verify.golines的定义:
tools.verify.%:
@if ! which $* &>/dev/null; then $(MAKE) tools.install.$*; fi
再来看下tools.install.$*规则:
.PHONY: install.golines
install.golines:
@$(GO) get -u github.com/segmentio/golines
通过tools.verify.%规则定义,我们可以知道,tools.verify.%会先检查工具是否安装,如果没有安装,就会执行tools.install.$*来安装。如此一来,当我们执行tools.verify.%目标时,如果系统没有安装 golines 命令,就会自动调用 go get安装,提高了 Makefile 的自动化程度。
技巧 4:把常用功能放在 /Makefile 中,不常用的放在分类 Makefile 中
一个项目,尤其是大型项目,有很多需要管理的地方,其中大部分都可以通过 Makefile 实现自动化操作。不过,为了保持 /Makefile 文件的整洁性,我们不能把所有的命令都添加在 /Makefile 文件中。
一个比较好的建议是,将常用功能放在 /Makefile 中,不常用的放在分类 Makefile 中,并在 /Makefile 中 include 这些分类 Makefile。
例如,IAM 项目的 /Makefile 集成了format、lint、test、build等常用命令,而将gen.errcode.code、gen.errcode.doc这类不常用的功能放在 scripts/make-rules/gen.mk 文件中。当然,我们也可以直接执行 make gen.errcode.code来执行gen.errcode.code伪目标。通过这种方式,既可以保证 /Makefile 的简洁、易维护,又可以通过make命令来运行伪目标,更加灵活。
技巧 5:编写可扩展的 Makefile
什么叫可扩展的 Makefile 呢?在我看来,可扩展的 Makefile 包含两层含义:
- 可以在不改变 Makefile 结构的情况下添加新功能。
- 扩展项目时,新功能可以自动纳入到 Makefile 现有逻辑中。
其中的第一点,我们可以通过设计合理的 Makefile 结构来实现。要实现第二点,就需要我们在编写 Makefile 时采用一定的技巧,例如多用通配符、自动变量、函数等。这里我们来看一个例子,可以让你更好地理解。
在我们 IAM 实战项目的golang.mk中,执行 make go.build 时能够构建 cmd/ 目录下的所有组件,也就是说,当有新组件添加时, make go.build 仍然能够构建新增的组件,这就实现了上面说的第二点。
具体实现方法如下:
COMMANDS ?= $(filter-out %.md, $(wildcard ${ROOT_DIR}/cmd/*))
BINS ?= $(foreach cmd,${COMMANDS},$(notdir ${cmd}))
.PHONY: go.build
go.build: go.build.verify $(addprefix go.build., $(addprefix $(PLATFORM)., $(BINS)))
.PHONY: go.build.%
go.build.%:
$(eval COMMAND := $(word 2,$(subst ., ,$*)))
$(eval PLATFORM := $(word 1,$(subst ., ,$*)))
$(eval OS := $(word 1,$(subst _, ,$(PLATFORM))))
$(eval ARCH := $(word 2,$(subst _, ,$(PLATFORM))))
@echo "===========> Building binary $(COMMAND) $(VERSION) for $(OS) $(ARCH)"
@mkdir -p $(OUTPUT_DIR)/platforms/$(OS)/$(ARCH)
@CGO_ENABLED=0 GOOS=$(OS) GOARCH=$(ARCH) $(GO) build $(GO_BUILD_FLAGS) -o $(OUTPUT_DIR)/platforms/$(OS)/$(ARCH)/$(COMMAND)$(GO_OUT_EXT) $(ROOT_PACKAGE)/cmd/$(COMMAND)
当执行make go.build 时,会执行 go.build 的依赖 $(addprefix go.build., $(addprefix $(PLATFORM)., $(BINS))) ,addprefix函数最终返回字符串 go.build.linux_amd64.iamctl go.build.linux_amd64.iam-authz-server go.build.linux_amd64.iam-apiserver ... ,这时候就会执行 go.build.% 伪目标。
在 go.build.% 伪目标中,通过 eval、word、subst 函数组合,算出了 COMMAND 的值 iamctl/iam-apiserver/iam-authz-server/...,最终通过 $(ROOT_PACKAGE)/cmd/$(COMMAND) 定位到需要构建的组件的 main 函数所在目录。
上述实现中有两个技巧,你可以注意下。首先,通过
COMMANDS ?= $(filter-out %.md, $(wildcard ${ROOT_DIR}/cmd/*))
BINS ?= $(foreach cmd,${COMMANDS},$(notdir ${cmd}))
获取到了 cmd/ 目录下的所有组件名。
接着,通过使用通配符和自动变量,自动匹配到go.build.linux_amd64.iam-authz-server 这类伪目标并构建。
可以看到,想要编写一个可扩展的 Makefile,熟练掌握 Makefile 的用法是基础,更多的是需要我们动脑思考如何去编写 Makefile。
技巧 6:将所有输出存放在一个目录下,方便清理和查找
在执行 Makefile 的过程中,会输出各种各样的文件,例如 Go 编译后的二进制文件、测试覆盖率数据等,我建议你把这些文件统一放在一个目录下,方便后期的清理和查找。通常我们可以把它们放在_output这类目录下,这样清理时就很方便,只需要清理_output文件夹就可以,例如:
.PHONY: go.clean
go.clean:
@echo "===========> Cleaning all build output"
@-rm -vrf $(OUTPUT_DIR)
这里要注意,要用-rm,而不是 rm,防止在没有_output目录时,执行make go.clean报错。
技巧 7:使用带层级的命名方式
通过使用带层级的命名方式,例如tools.verify.swagger ,我们可以实现目标分组管理。这样做的好处有很多。首先,当 Makefile 有大量目标时,通过分组,我们可以更好地管理这些目标。其次,分组也能方便理解,可以通过组名一眼识别出该目标的功能类别。最后,这样做还可以大大减小目标重名的概率。
例如,IAM 项目的 Makefile 就大量采用了下面这种命名方式。
.PHONY: gen.run
gen.run: gen.clean gen.errcode gen.docgo
.PHONY: gen.errcode
gen.errcode: gen.errcode.code gen.errcode.doc
.PHONY: gen.errcode.code
gen.errcode.code: tools.verify.codegen
...
.PHONY: gen.errcode.doc
gen.errcode.doc: tools.verify.codegen
...
技巧 8:做好目标拆分
还有一个比较实用的技巧:我们要合理地拆分目标。比如,我们可以将安装工具拆分成两个目标:验证工具是否已安装和安装工具。通过这种方式,可以给我们的 Makefile 带来更大的灵活性。例如:我们可以根据需要选择性地执行其中一个操作,也可以两个操作一起执行。
这里来看一个例子:
gen.errcode.code: tools.verify.codegen
tools.verify.%:
@if ! which $* &>/dev/null; then $(MAKE) tools.install.$*; fi
.PHONY: install.codegen
install.codegen:
@$(GO) install ${ROOT_DIR}/tools/codegen/codegen.go
上面的 Makefile 中,gen.errcode.code 依赖了 tools.verify.codegen,tools.verify.codegen 会先检查 codegen 命令是否存在,如果不存在,再调用 install.codegen 来安装 codegen 工具。
如果我们的 Makefile 设计是:
gen.errcode.code: install.codegen
那每次执行 gen.errcode.code 都要重新安装 codegen 命令,这种操作是不必要的,还会导致 make gen.errcode.code 执行很慢。
技巧 9:设置 OPTIONS
编写 Makefile 时,我们还需要把一些可变的功能通过 OPTIONS 来控制。为了帮助你理解,这里还是拿 IAM 项目的 Makefile 来举例。
假设我们需要通过一个选项 V ,来控制是否需要在执行 Makefile 时打印详细的信息。这可以通过下面的步骤来实现。
首先,在 /Makefile 中定义 USAGE_OPTIONS 。定义 USAGE_OPTIONS 可以使开发者在执行 make help 后感知到此 OPTION,并根据需要进行设置。
define USAGE_OPTIONS
Options:
...
BINS The binaries to build. Default is all of cmd.
...
...
V Set to 1 enable verbose build. Default is 0.
endef
export USAGE_OPTIONS
接着,在scripts/make-rules/common.mk文件中,我们通过判断有没有设置 V 选项,来选择不同的行为:
ifndef V
MAKEFLAGS += --no-print-directory
endif
当然,我们还可以通过下面的方法来使用 V :
ifeq ($(origin V), undefined)
MAKEFLAGS += --no-print-directory
endif
上面,我介绍了 VOPTION,我们在 Makefile 中通过判断有没有定义 V ,来执行不同的操作。其实还有一种 OPTION,这种 OPTION 的值我们在 Makefile 中是直接使用的,例如 BINS。针对这种 OPTION,我们可以通过以下方式来使用:
BINS ?= $(foreach cmd,${COMMANDS},$(notdir ${cmd}))
...
go.build: go.build.verify $(addprefix go.build., $(addprefix $(PLATFORM)., $(BINS)))
也就是说,通过 ?= 来判断 BINS 变量有没有被赋值,如果没有,则赋予等号后的值。接下来,就可以在 Makefile 规则中使用它。
技巧 10:定义环境变量
我们可以在 Makefile 中定义一些环境变量,例如:
GO := go
GO_SUPPORTED_VERSIONS ?= 1.13|1.14|1.15|1.16|1.17
GO_LDFLAGS += -X $(VERSION_PACKAGE).GitVersion=$(VERSION) \
-X $(VERSION_PACKAGE).GitCommit=$(GIT_COMMIT) \
-X $(VERSION_PACKAGE).GitTreeState=$(GIT_TREE_STATE) \
-X $(VERSION_PACKAGE).BuildDate=$(shell date -u +'%Y-%m-%dT%H:%M:%SZ')
ifneq ($(DLV),)
GO_BUILD_FLAGS += -gcflags "all=-N -l"
LDFLAGS = ""
endif
GO_BUILD_FLAGS += -tags=jsoniter -ldflags "$(GO_LDFLAGS)"
...
FIND := find . ! -path './third_party/*' ! -path './vendor/*'
XARGS := xargs --no-run-if-empty
这些环境变量和编程中使用宏定义的作用是一样的:只要修改一处,就可以使很多地方同时生效,避免了重复的工作。
通常,我们可以将 GO、GO_BUILD_FLAGS、FIND 这类变量定义为环境变量。
技巧 11:自己调用自己
在编写 Makefile 的过程中,你可能会遇到这样一种情况:A-Target 目标命令中,需要完成操作 B-Action,而操作 B-Action 我们已经通过伪目标 B-Target 实现过。为了达到最大的代码复用度,这时候最好的方式是在 A-Target 的命令中执行 B-Target。方法如下:
tools.verify.%:
@if ! which $* &>/dev/null; then $(MAKE) tools.install.$*; fi
这里,我们通过 $(MAKE) 调用了伪目标 tools.install.$* 。要注意的是,默认情况下,Makefile 在切换目录时会输出以下信息:
$ make tools.install.codegen
===========> Installing codegen
make[1]: Entering directory `/home/colin/workspace/golang/src/github.com/marmotedu/iam'
make[1]: Leaving directory `/home/colin/workspace/golang/src/github.com/marmotedu/iam'
如果觉得 Entering directory 这类信息很烦人,可以通过设置 MAKEFLAGS += --no-print-directory 来禁止 Makefile 打印这些信息。
Makefile 多线程
💡 注意,在设计Makefile的时候尤其注意对并行的设计,这一点非常重要~
makefile是定义的依赖顺序,如果没有考虑多线程编译,很大概率会出问题。
Makefile 支持多线程并发操作,会极大的缩短我们的编译时间,并且当我们修改了源文件之后,编译整个工程的时候,make 命令只会编译我们修改过的文件,没有修改的文件不用重新编译,不增加或者是删除工程中的文件,Makefile 基本上不用去修改。
因为CPU是一个影响编译速度的重要因素,所以make -j带上一个参数,可以把项目在进行中的并行编译,现在服务器上的CPU差不多都是多核多线程的,所以完全可以用make -j4,让make最多允许4个编译进程同时执行,这样可以更有效的利用CPU资源。
在多处理器上运行多个作业显然是有意义的,但是在单处理器上运行多个作业也是非常有用的。这是因为磁盘I/O的延迟和大多数系统上的大量缓存。例如,如果诸如gcc的进程空闲等待盘I/O,则可能是诸如mv、yacc或ar的另一任务的数据当前在存储器中。在这种情况下,最好允许具有可用数据的任务继续进行。一般来说,在单处理器上运行两个任务的make几乎总是比运行一个任务快,并且三个甚至四个任务比两个任务快的情况并不少见。
使用--jobs=2告诉make在可能的情况下并行更新两个目标。
--jobs选项可以不带数字使用。如果是这样,make将产生与要更新的目标一样多的作业。这通常是一个坏主意,因为大量的作业通常会淹没处理器,甚至比单个作业运行得慢得多。
💡简单的一个案例如下:
不用
-j参数:
make linux-amd64 16.97s user 14.16s system 117% cpu
26.595 total
使用
-j参数:
cpu信息:
cpu family : 6
cpu MHz : 2419.199
cpu cores : 4
cpuid level : 27
🚀 编译结果如下:
make -j4 linux-amd64 9.35s user 2.97s system 104% cpu 11.772 total
📜 对上面的解释:
| 字段 | 含义 |
|---|---|
| make -j 6 | 使用6个并发进程编译 |
| linux-amd64 | 编译的目标平台为linux-amd64 |
| 10.29s user | 用户空间占用CPU时间10.29秒 |
| 4.31s system | 内核空间占用CPU时间4.31秒 |
| 106% cpu | 总CPU使用率为106% |
| 13.774 total | 总耗时13.774秒 |
使用的 subshell 也很重要,上面是对 zsh 的测试,而下面是 在 bash测试,至于Windows可以自己测试玩玩,应该更慢
这并不奇怪。Windows系统比Linux慢,
ash比bash有优势。ash的性能提升更为明显-约快50%。Linux系统使用ash时性能最佳,使用bash(命名为“bash”时)时性能最慢。
# make -j4 linux-amd64
real 0m11.284s
user 0m8.670s
sys 0m2.863s
我们指定两个的测试:
# make --jobs=2 linux-amd64
real 0m11.283s
user 0m8.502s
sys 0m2.901s
Makefile 参数
| 参数选项 | 功能 |
|---|---|
| -b,-m | 忽略,提供其他版本 make 的兼容性 |
| -B,–always-make | 强制重建所有的规则目标,不根据规则的依赖描述决定是否重建目标文件。 |
| -C DIR,–directory=DIR | 在读取 Makefile 之前,进入到目录 DIR,然后执行 make。当存在多个 “-C” 选项的时候,make 的最终工作目录是第一个目录的相对路径。 |
| -d | make 在执行的过程中打印出所有的调试信息,包括 make 认为那些文件需要重建,那些文件需要比较最后的修改时间、比较的结果,重建目标是用的命令,遗憾规则等等。使用 “-d” 选项我们可以看到 make 构造依赖关系链、重建目标过程中的所有的信息。 |
–debug[=OPTIONS] | make 执行时输出调试信息,可以使用 “OPTIONS” 控制调试信息的级别。默认是 “OPTIONS=b” ,“OPTIONS” 的可值为以下这些,首字母有效:all、basic、verbose、implicit、jobs、makefile。 |
| -e,–enveronment -overrides | 使用环境变量定义覆盖 Makefile 中的同名变量定义。 |
| -f=FILE,–file=FILE, --makefile=FILE | 指定文件 “FILE” 为 make 执行的 Makefile 文件 |
| -p,–help | 打印帮助信息。 |
| -i,–ignore-errors | 执行过程中忽略规则命令执行的错误。 |
| -I DIR,–include-dir=DIR | 指定包含 Makefile 文件的搜索目录,在Makefile中出现另一个 “include” 文件时,将在 “DIR” 目录下搜索。多个 “-i” 指定目录时,搜索目录按照指定的顺序进行。 |
| -j [JOBS],–jobs[=JOBS] | 可指定同时执行的命令数目,没有 “-j” 的情况下,执行的命令数目将是系统允许的最大可能数目,存在多个 “-j” 目标时,最后一个目标指定的 JOBS 数有效。 |
| -k,–keep-going | 执行命令错误时不终止 make 的执行,make 尽最大可能执行所有的命令,直至出现知名的错误才终止。 |
| -l load,–load-average=[=LOAD],–max-load[=LOAD] | 告诉 make 在存在其他任务执行的时候,如果系统负荷超过 “LOAD”,不在启动新的任务。如果没有指定 “LOAD” 的参数 “-l” 选项将取消之前 “-l” 指定的限制。 |
| -n,–just-print,–dry-run | 只打印执行的命令,但是不执行命令。 |
| -o FILE,–old-file=FILE, --assume-old=FILE | 指定 "FILE"文件不需要重建,即使是它的依赖已经过期;同时不重建此依赖文件的任何目标。注意:此参数不会通过变量 “MAKEFLAGS” 传递给子目录进程。 |
| -p,–print-date-base | 命令执行之前,打印出 make 读取的 Makefile 的所有数据,同时打印出 make 的版本信息。如果只需要打印这些数据信息,可以使用 “make -qp” 命令,查看 make 执行之前预设的规则和变量,可使用命令 “make -p -f /dev/null” |
| -q,-question | 称为 “询问模式” ;不运行任何的命令,并且无输出。make 只返回一个查询状态。返回状态 0 表示没有目标表示重建,返回状态 1 表示存在需要重建的目标,返回状态 2 表示有错误发生。 |
| -r,–no-builtin-rules | 取消所有的内嵌函数的规则,不过你可以在 Makefile 中使用模式规则来定义规则。同时选项 “-r” 会取消所有后缀规则的隐含后缀列表,同样我们可以在 Makefile 中使用 “.SUFFIXES”,定义我们的后缀名的规则。“-r” 选项不会取消 make 内嵌的隐含变量。 |
| -R,–no-builtin-variabes | 取消 make 内嵌的隐含变量,不过我们可以在 Makefile 中明确定义某些变量。注意:“-R” 和 “-r” 选项同时打开,因为没有了隐含变量,所以隐含规则将失去意义。 |
| -s,–silent,–quiet | 取消命令执行过程中的打印。 |
| -S,–no-keep-going, --stop | 取消 “-k” 的选项在递归的 make 过程中子 make 通过 “MAKEFLAGS” 变量继承了上层的命令行选项那个。我们可以在子 make 中使用“-S”选项取消上层传递的 “-k” 选项,或者取消系统环境变量 “MAKEFLAGS” 中 "-k"选项。 |
| -t,–touch | 和 Linux 的 touch 命令实现功能相同,更新所有的目标文件的时间戳到当前系统时间。防止 make 对所有过时目标文件的重建。 |
| -v,version | 查看make的版本信息。 |
| -w,–print-directory | 在 make 进入一个子目录读取 Makefile 之前打印工作目录,这个选项可以帮助我们调试 Makefile,跟踪定位错误。使用 “-C” 选项时默认打开这个选项。 |
| –no-print-directory | 取消 “-w” 选项。可以是 用在递归的 make 调用的过程中 ,取消 “-C” 参数的默认打开 “-w” 的功能。 |
| -W FILE,–what-if=FILE, --new-file=FILE, --assume-file=FILE | 设定文件 “FILE” 的时间戳为当前的时间,但不更改文件实际的最后修改时间。此选项主要是为了实现对所有依赖于文件 “FILE” 的目标的强制重建。 |
| –warn-undefined-variables | 在发现 Makefile 中存在没有定义的变量进行引用时给出告警信息。此功能可以帮助我们在调试一个存在多级嵌套变量引用的复杂 Makefile。但是建议在书写的时候尽量避免超过三级以上的变量嵌套引用。 |
常用的参数
-p: 输出 Makefile 所有信息包括规则和变量,可以和-q不执行命令结合-B: 所有目标都需要更新、重新编译-d:相当于make -debug=a输出所有的调试信息。(会非常的多)-w:输出运行makefile之前和之后的信息。这个参数对于跟踪嵌套式调用make时很有用。
补充:Makefile Go语言交叉编译
我们很多时候都需要实现交叉编译,尤其是对于 Go语言 来说,这一点也很重要。
我们平常都很喜欢用 Makefile 管理
获取版本号
Go语言中获取版本的方法可以使用 go env GOOS
❯ go env GOOS
linux
同样的我们可以获取到指令集:
❯ go env GOARCH
amd64
那么在 Makefile 中我们使用 shell 的方式获取:
GOOS ?= $(shell go env GOOS)
GOARCH ?= $(shell go env GOARCH)
build:
go build -o out/greeting-$(GOOS)-$(GOARCH) .
实现交叉编译
buildx:
GOOS=dorwin GOARCH=amd64 make build
GOOS=dorwin GOARCH=arm64 make build
GOOS=linux GOARCH=amd64 make build
GOOS=linux GOARCH=arm64 make build
GOOS=linux GOARCH=arm64 只是在当前那一hang
总结
规范的 Makefile 文件需要的步骤:
- v首先,你需要熟练掌握 Makefile 的语法。我建议你重点掌握以下语法:Makefile 规则语法、伪目标、变量赋值、特殊变量、自动化变量。
- 接着,我们需要提前规划 Makefile 要实现的功能。一个大型 Go 项目通常需要实现以下功能:代码生成类命令、格式化类命令、静态代码检查、 测试类命令、构建类命令、Docker 镜像打包类命令、部署类命令、清理类命令,等等。
- 然后,我们还需要通过 Makefile 功能分类、文件分层、复杂命令脚本化等方式,来设计一个合理的 Makefile 结构。
- 最后,我们还需要掌握一些 Makefile 编写技巧,例如:善用通配符、自动变量和函数;编写可扩展的 Makefile;使用带层级的命名方式,等等。通过这些技巧,可以进一步保证我们编写出一个高质量的 Makefile。
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©
LInks
- https://time.geekbang.org/column/article/389115
- https://github.com/cubxxw/iam/blob/master/Makefile
- https://seisman.github.io/how-to-write-makefile/rules.html
- https://colynn.github.io/2020-03-03-using_makefile/